论文链接:https://arxiv.org/pdf/2308.12966
代码链接:https://github.com/QwenLM/Qwen-VL
摘要
在本研究中,我们推出了 Qwen-VL 系列,这是一组大规模视觉语言模型 (LVLM),旨在感知和理解文本和图像。以 Qwen-LM 为基础,我们通过精心设计的 (i) 视觉感知器、(ii) 输入输出接口、(iii) 三阶段训练流程以及 (iv) 多语言多模态清洗语料库赋予其视觉能力。除了传统的图像描述和问答功能外,我们还通过对齐图像-标题-框三元组实现了 Qwen-VL 的语义基础和文本阅读能力。由此产生的模型,包括 Qwen-VL 和 Qwen-VL-Chat,在一系列以视觉为中心的基准测试(例如,图像解释、问答和视觉语义基础)以及不同设置(例如,zero-shot、few-shot)中,在类似模型规模下创下了通用模型的新纪录。此外,在真实世界对话基准测试中,我们经过指令调优的 Qwen-VL-Chat 也展现出优于现有视觉语言聊天机器人的优势。所有模型均已公开,以方便未来研究。
1.介绍
近年来,大语言模型 (LLM) 因其强大的文本生成和理解能力而备受关注。这些模型可以通过指令微调进一步匹配用户意图,展现出强大的交互能力,并有望提升智能助手的生产力。然而,原生大语言模型仅限于纯文本世界,缺乏处理其他常见模态(例如图像、语音和视频)的能力,导致其应用范围受到极大限制。受此启发,一组大型视觉语言模型 (LVLM) 应运而生,旨在增强大语言模型对视觉信号的感知和理解能力。这些大规模视觉语言模型在解决现实世界中以视觉为中心的问题方面展现出巨大的潜力。
然而,尽管人们已经开展了大量工作来探索 LVLM 的局限性和潜力,但当前的开源 LVLM 始终存在训练和优化不足的问题,因此远远落后于专有模型,这阻碍了 LVLM 在开源社区的进一步探索和应用。此外,由于现实世界的视觉场景非常复杂,细粒度的视觉理解对于 LVLM 有效、准确地辅助人类至关重要。但朝着这个方向的尝试很少,大多数开源 LVLM 仍然以粗粒度的方式感知图像,缺乏执行细粒度感知(例如物体定位或文本阅读)的能力。
在本文中,我们探索了一条出路,并介绍了开源 Qwen 家族的最新成员:Qwen-VL 系列。Qwen-VL 是基于 Qwen-7B 语言模型的一系列高性能、多功能的视觉语言基础模型。我们通过引入一种新的视觉感知器(包括语言对齐的视觉编码器和位置感知 adapter),为 LLM 基础模型赋予了视觉能力。整体模型架构和输入输出接口非常简洁,我们精心设计了三阶段训练流程,以便在海量图文语料库上优化整个模型。
我们预训练的检查点 Qwen-VL 能够感知和理解视觉输入,根据给定的提示生成所需的响应,并完成各种视觉语言任务,例如图像解释、问答、面向文本的问答和视觉基础。Qwen-VL-Chat 是基于 Qwen-VL 的指令微调的视觉语言聊天机器人。如图 2 所示,Qwen-VL-Chat 能够与用户交互,并根据用户的意图感知输入图像。
具体来说,Qwen-VL系列模型的特点包括:
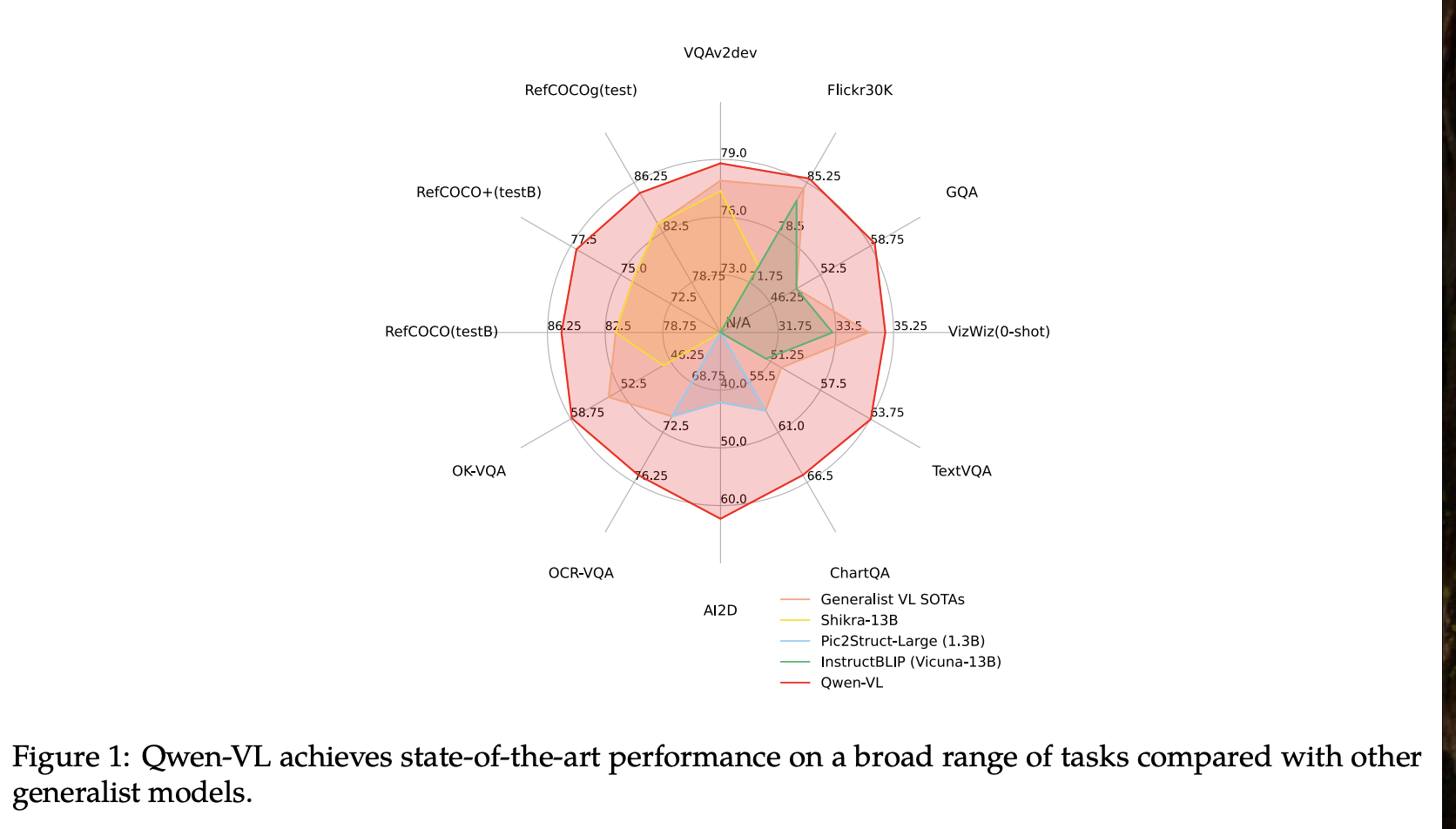
- Leading performance:与同等规模的同类产品相比,Qwen-VL 在众多以视觉为中心的理解基准测试中实现了顶级准确率。此外,Qwen-VL 的出色性能不仅涵盖了字幕、问答、定位等传统基准测试,还涵盖了一些近期推出的对话基准测试。
- Multi-lingual:与 Qwen-LM 类似,Qwen-VL 基于多语言图文数据进行训练,其中大量语料为英文和中文。因此,Qwen-VL 自然支持英文、中文及多种语言指令。
- Multi-image:在训练阶段,我们允许任意交错的图像文本数据作为 Qwen-VL 的输入。此功能使我们的 Qwen-Chat-VL 能够在输入多幅图像时进行比较、理解和分析上下文。
- Fine-grained visual understanding:得益于我们在训练中使用的更高分辨率输入规模和细粒度语料库,Qwen-VL 展现出极具竞争力的细粒度视觉理解能力。与现有的视觉语言模型相比,我们的 Qwen-VL 在定位、文本阅读、面向文本的问答和细粒度对话方面均拥有更佳的表现。

2.方法
2.1 Model Architecture

Qwen-VL 整体网络架构由三个部分组成,模型参数详情如表1所示:
Large Language Model。Qwen-VL 采用大语言模型作为其基础组件。该模型使用 Qwen-7B 中的预训练权重进行初始化。
Visual Encoder。Qwen-VL 的视觉编码器采用 Vision Transformer (ViT) 架构,并使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像都会调整到特定分辨率。视觉编码器通过将图像分割成步长为 14 的块来处理图像,从而生成一组图像特征。
Position-aware Vision-Language Adapter。为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一个视觉-语言 adapter 来压缩图像特征。该 adapter 包含一个随机初始化的单层交叉注意力模块。该模块使用一组可训练向量(Embedding)作为 query 向量,并使用来自视觉编码器的图像特征作为交叉注意力操作的 key。该机制将视觉特征序列压缩为固定长度 256。query 数量的变化如附录 E.2 所示。此外,考虑到位置信息对于细粒度图像理解的重要性,在交叉注意力机制的 query-key 对中加入了二维绝对位置编码,以减少压缩过程中位置细节的潜在损失。压缩后的长度为 256 的图像特征序列随后被输入到大语言模型中。
2.2 Inputs and Outputs
Image Input。图像经过视觉编码器和 adapter 处理,生成固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,在图像特征序列的开头和结尾分别附加两个特殊token( 和 ),分别表示图像内容的开始和结束。
Bounding Box Input and Output。为了增强模型的细粒度视觉理解和基础能力,Qwen-VL 的训练涉及区域描述、问题和检测形式的数据。与传统的图像文本描述或问题任务不同,该任务需要模型准确理解并生成指定格式的区域描述。对于任何给定的边界框,都会应用归一化处理(在 [0, 1000) 范围内)并将其转换为指定的字符串格式:“”。该字符串被标记为文本,无需额外的位置词汇。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加了两个特殊 token( 和 )。此外,为了将边界框与其对应的描述性单词或句子恰当地关联起来,引入了另一组特殊 token( 和 ),标记边界框所引用的内容。
3.Training
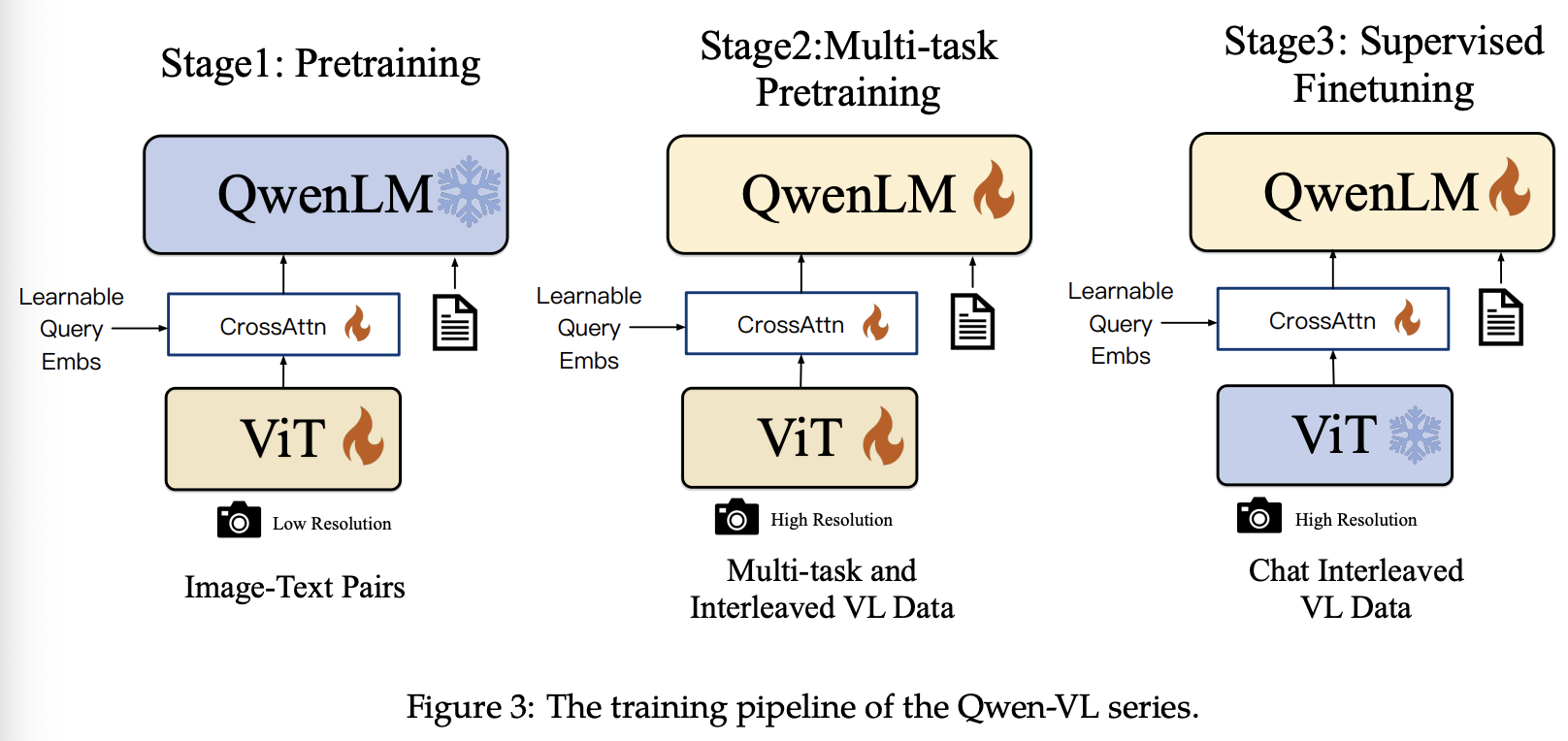
如图3所示,Qwen-VL模型的训练过程包括三个阶段:两个阶段的预训练和最后的指令微调训练阶段。
3.1 Pre-training
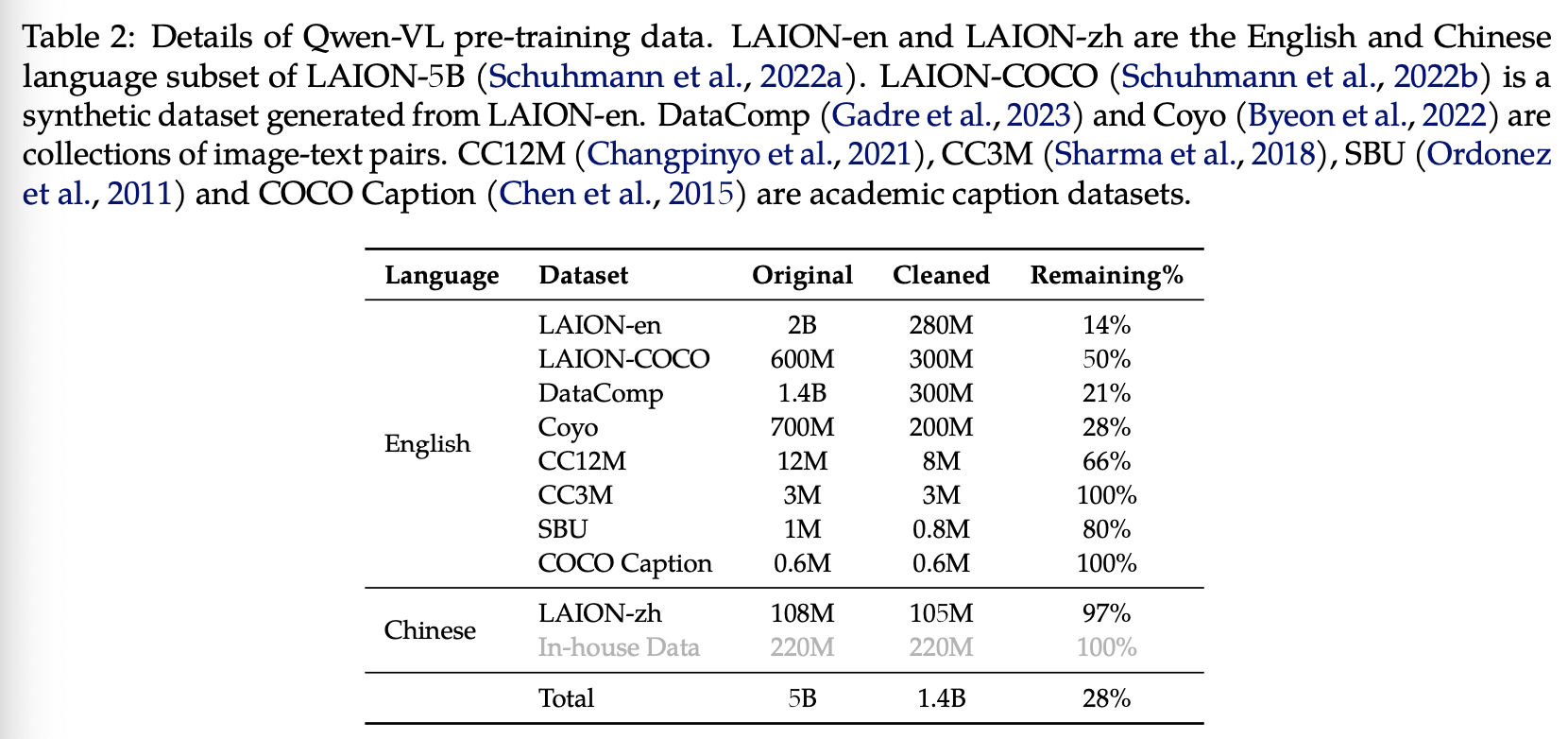
在预训练的第一阶段,我们主要利用一个大规模、弱标记、从网络爬取的图文对数据集。我们的预训练数据集由多个公开来源和一些内部数据组成。我们努力清理数据集中的某些模式。如表 2 所示,原始数据集共包含 50 亿个图文对,清理后剩余 14 亿个数据,其中 77.3% 为英文(文本)数据,22.7% 为中文(文本)数据。
我们冻结大语言模型,在此阶段仅优化视觉编码器和视觉语言 adapter。输入图像大小调整为 224 × 224。训练目标是最小化文本 token 的交叉熵。最大学习率为 2e-4,训练过程中图像-文本对的批次大小为 30720,整个第一阶段的预训练持续 50,000 步,消耗约 15 亿个图像-文本样本。更多超参数详见附录 C,本阶段的收敛曲线如图 6 所示。
3.2 Multi-task Pre-training
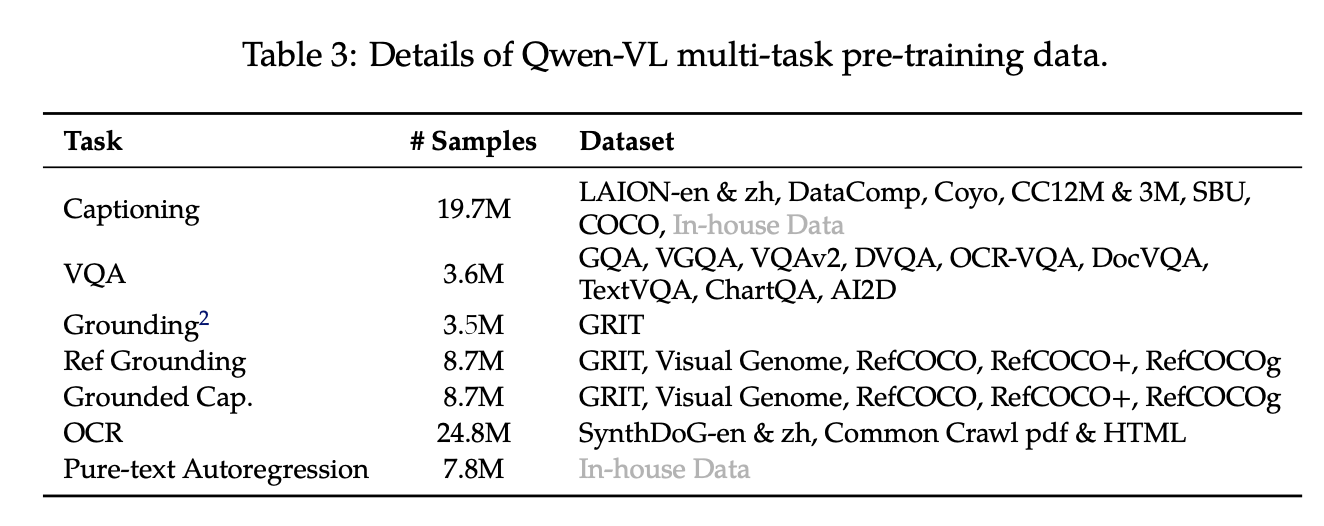
在多任务预训练的第二阶段,我们引入了高质量、细粒度的 VL 标注数据,这些数据具有更高的输入分辨率和交错的图像文本数据。如表 3 所示,我们同时对 Qwen-VL 进行了 7 项任务的训练。对于文本生成,我们使用内部收集的语料库来维持 LLM 的能力。caption 数据与表 2 相同,但样本量少得多且不包括 LAION-COCO。对于 VQA 任务,我们混合使用了公开可用的数据,包括 GQA、VGQA、VQAv2、DVQA、OCRVQA 和 DocVQA。我们遵循 Kosmos-2 的做法,使用 GRIT 数据集进行基础任务,并进行了一些修改。对于参考基准和基准字幕二元性任务,我们从 GRIT 、Visual Genome、RefCOCO、RefCOCO+ 和 RefCOCOg 构建训练样本。为了改进面向文本的任务,我们从 Common Crawl 收集了 PDF 和 HTML 格式的数据,并参考 (Kim et al., 2022) 的方法,生成了以自然风景为背景的英文和中文合成 OCR 数据。最后,我们将相同的任务数据打包成长度为 2048 的序列,构建了交错的图像文本数据。
我们将视觉编码器的输入分辨率从 224 × 224 提升到 448 × 448,从而减少了图像下采样造成的信息损失。此外,我们在附录 E.3 中针对更高分辨率的视觉转换器 (Vision Transformer) 消融了窗口注意力机制和全局注意力机制。我们解锁了大语言模型并训练了整个模型。训练目标与预训练阶段相同。
3.3 Supervised Fine-tuning
在此阶段,我们通过指令微调对 Qwen-VL 预训练模型进行微调,以增强其指令遵循和对话能力,最终形成了交互式的 Qwen-VL-Chat 模型。多模态指令微调数据主要来源于 LLM 自训练生成的字幕数据或对话数据,而这些数据通常仅针对单图像对话和推理,且仅限于图像内容理解。我们通过人工标注、模型生成和策略串联构建了一组额外的对话数据,将本地化和多图像理解能力融入 Qwen-VL 模型。我们确认该模型能够有效地将这些能力迁移到更广泛的语言和问题类型。此外,我们在训练过程中混合使用多模态和纯文本对话数据,以确保模型在对话能力方面的普适性。指令微调数据量达 35 万。在此阶段,我们冻结视觉编码器,并优化语言模型和 adapter 模块。此阶段的数据格式演示见附录 B.2。